From A First Course in Linear Algebra
Version 2.12
© 2004.
Licensed under the GNU Free Documentation License.
http://linear.ups.edu/
There are four natural subsets associated with a matrix. We have met
three already: the null space, the column space and the row space. In this
section we will introduce a fourth, the left null space. The objective of this
section is to describe one procedure that will allow us to find linearly
independent sets that span each of these four sets of column vectors.
Along the way, we will make a connection with the inverse of a matrix, so
Theorem FS will tie together most all of this chapter (and the entire course so
far).
Definition LNS
Left Null Space
Suppose A is an
m × n matrix. Then the left
null space is defined as ℒ\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left ({A}^{t}\right ) ⊆ {ℂ}^{m}.
(This definition contains Notation LNS.) △
The left null space will not feature prominently in the sequel, but we can explain its name and connect it to row operations. Suppose y ∈ℒ\kern -1.95872pt \left (A\right ). Then by Definition LNS, {A}^{t}y = 0. We can then write
The product {y}^{t}A can be viewed as the components of y acting as the scalars in a linear combination of the rows of A. And the result is a “row vector”, {0}^{t} that is totally zeros. When we apply a sequence of row operations to a matrix, each row of the resulting matrix is some linear combination of the rows. These observations tell us that the vectors in the left null space are scalars that record a sequence of row operations that result in a row of zeros in the row-reduced version of the matrix. We will see this idea more explicitly in the course of proving Theorem FS.
Example LNS
Left null space
We will find the left null space of
|
A = \left [\array{
1 &−3&1\cr
−2 & 1 &1
\cr
1 & 5 &1\cr
9 &−4 &0 } \right ]
|
We transpose A and row-reduce,
|
{
A}^{t} = \left [\array{
1 &−2&1& 9\cr
−3 & 1 &5 &−4
\cr
1 & 1 &1& 0 } \right ]\mathop{\longrightarrow}\limits_{}^{\text{RREF}}\left [\array{
\text{1}&0&0& 2\cr
0&\text{1 } &0 &−3
\cr
0&0&\text{1}& 1 } \right ]
|
Applying Definition LNS and Theorem BNS we have
|
ℒ\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left ({A}^{t}\right ) = \left \langle \left \{\left [\array{
−2\cr
3
\cr
−1\cr
1 } \right ]\right \}\right \rangle
|
If you row-reduce A you will discover one zero row in the reduced row-echelon form. This zero row is created by a sequence of row operations, which in total amounts to a linear combination, with scalars {a}_{1} = −2, {a}_{2} = 3, {a}_{3} = −1 and {a}_{4} = 1, on the rows of A and which results in the zero vector (check this!). So the components of the vector describing the left null space of A provide a relation of linear dependence on the rows of A. ⊠
We have three ways to build the column space of a matrix. First, we can use just the definition, Definition CSM, and express the column space as a span of the columns of the matrix. A second approach gives us the column space as the span of some of the columns of the matrix, but this set is linearly independent (Theorem BCS). Finally, we can transpose the matrix, row-reduce the transpose, kick out zero rows, and transpose the remaining rows back into column vectors. Theorem CSRST and Theorem BRS tell us that the resulting vectors are linearly independent and their span is the column space of the original matrix.
We will now demonstrate a fourth method by way of a rather complicated example. Study this example carefully, but realize that its main purpose is to motivate a theorem that simplifies much of the apparent complexity. So other than an instructive exercise or two, the procedure we are about to describe will not be a usual approach to computing a column space.
Example CSANS
Column space as null space
Lets find the column space of the matrix
A below
with a new approach.
|
A = \left [\array{
10 & 0 & 3 & 8 & 7\cr
−16 &−1 &−4 &−10 &−13
\cr
−6 & 1 &−3& −6 & −6\cr
0 & 2 &−2 & −3 & −2
\cr
3 & 0 & 1 & 2 & 3\cr
−1 &−1 & 1 & 1 & 0 } \right ]
|
By Theorem CSCS we know that the column vector b is in the column space of A if and only if the linear system ℒS\kern -1.95872pt \left (A,\kern 1.95872pt b\right ) is consistent. So let’s try to solve this system in full generality, using a vector of variables for the vector of constants. In other words, which vectors b lead to consistent systems? Begin by forming the augmented matrix \left [\left .A\kern 1.95872pt \right \vert \kern 1.95872pt b\right ] with a general version of b,
|
\left [\left .A\kern 1.95872pt \right \vert \kern 1.95872pt b\right ] = \left [\array{
10 & 0 & 3 & 8 & 7 &{b}_{1}
\cr
−16&−1&−4&−10&−13&{b}_{2}
\cr
−6 & 1 &−3& −6 & −6 &{b}_{3}
\cr
0 & 2 &−2& −3 & −2 &{b}_{4}
\cr
3 & 0 & 1 & 2 & 3 &{b}_{5}
\cr
−1 &−1& 1 & 1 & 0 &{b}_{6} } \right ]
|
To identify solutions we will row-reduce this matrix and bring it to reduced row-echelon form. Despite the presence of variables in the last column, there is nothing to stop us from doing this. Except our numerical routines on calculators can’t be used, and even some of the symbolic algebra routines do some unexpected maneuvers with this computation. So do it by hand. Yes, it is a bit of work. But worth it. We’ll still be here when you get back. Notice along the way that the row operations are exactly the same ones you would do if you were just row-reducing the coefficient matrix alone, say in connection with a homogeneous system of equations. The column with the {b}_{i} acts as a sort of bookkeeping device. There are many different possibilities for the result, depending on what order you choose to perform the row operations, but shortly we’ll all be on the same page. Here’s one possibility (you can find this same result by doing additional row operations with the fifth and sixth rows to remove any occurrences of {b}_{1} and {b}_{2} from the first four rows of your result):
Our goal is to identify those vectors b which make ℒS\kern -1.95872pt \left (A,\kern 1.95872pt b\right ) consistent. By Theorem RCLS we know that the consistent systems are precisely those without a leading 1 in the last column. Are the expressions in the last column of rows 5 and 6 equal to zero, or are they leading 1’s? The answer is: maybe. It depends on b. With a nonzero value for either of these expressions, we would scale the row and produce a leading 1. So we get a consistent system, and b is in the column space, if and only if these two expressions are both simultaneously zero. In other words, members of the column space of A are exactly those vectors b that satisfy
Hmmm. Looks suspiciously like a homogeneous system of two equations with six variables. If you’ve been playing along (and we hope you have) then you may have a slightly different system, but you should have just two equations. Form the coefficient matrix and row-reduce (notice that the system above has a coefficient matrix that is already in reduced row-echelon form). We should all be together now with the same matrix,
|
L = \left [\array{
\text{1}&0& 3 &−1&3& 1\cr
0&\text{1 } &−2 & 1 &1 &−1 } \right ]
|
So, C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ) and we can apply Theorem BNS to obtain a linearly independent set to use in a span construction,
|
C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ) = \left \langle \left \{\left [\array{
−3\cr
2
\cr
1\cr
0
\cr
0\cr
0 } \right ],\kern 1.95872pt \left [\array{
1\cr
−1
\cr
0\cr
1
\cr
0\cr
0 } \right ],\kern 1.95872pt \left [\array{
−3\cr
−1
\cr
0\cr
0
\cr
1\cr
0 } \right ],\kern 1.95872pt \left [\array{
−1\cr
1
\cr
0\cr
0
\cr
0\cr
1 } \right ]\right \}\right \rangle
|
Whew! As a postscript to this central example, you may wish to convince yourself that the four vectors above really are elements of the column space? Do they create consistent systems with A as coefficient matrix? Can you recognize the constant vector in your description of these solution sets?
OK, that was so much fun, let’s do it again. But simpler this time. And we’ll all get the same results all the way through. Doing row operations by hand with variables can be a bit error prone, so let’s see if we can improve the process some. Rather than row-reduce a column vector b full of variables, let’s write b = {I}_{6}b and we will row-reduce the matrix {I}_{6} and when we finish row-reducing, then we will compute the matrix-vector product. You should first convince yourself that we can operate like this (this is the subject of a future homework exercise). Rather than augmenting A with b, we will instead augment it with {I}_{6} (does this feel familiar?),
|
M = \left [\array{
10 & 0 & 3 & 8 & 7 &1&0&0&0&0&0\cr
−16 &−1 &−4 &−10 &−13 &0 &1 &0 &0 &0 &0
\cr
−6 & 1 &−3& −6 & −6 &0&0&1&0&0&0\cr
0 & 2 &−2 & −3 & −2 &0 &0 &0 &1 &0 &0
\cr
3 & 0 & 1 & 2 & 3 &0&0&0&0&1&0\cr
−1 &−1 & 1 & 1 & 0 &0 &0 &0 &0 &0 &1 } \right ]
|
We want to row-reduce the left-hand side of this matrix, but we will apply the same row operations to the right-hand side as well. And once we get the left-hand side in reduced row-echelon form, we will continue on to put leading 1’s in the final two rows, as well as clearing out the columns containing those two additional leading 1’s. It is these additional row operations that will ensure that we all get to the same place, since the reduced row-echelon form is unique (Theorem RREFU),
|
N = \left [\array{
1&0&0&0& 2 &0&0& 1 &−1& 2 &−1\cr
0&1 &0 &0 &−3 &0 &0 &−2 & 3 &−3 & 3
\cr
0&0&1&0& 1 &0&0& 1 & 1 & 3 & 3\cr
0&0 &0 &1 &−2 &0 &0 &−2 & 1 &−4 & 0
\cr
0&0&0&0& 0 &1&0& 3 &−1& 3 & 1\cr
0&0 &0 &0 & 0 &0 &1 &−2 & 1 & 1 &−1
} \right ]
|
We are after the final six columns of this matrix, which we will multiply by b
|
J = \left [\array{
0&0& 1 &−1& 2 &−1\cr
0&0 &−2 & 3 &−3 & 3
\cr
0&0& 1 & 1 & 3 & 3\cr
0&0 &−2 & 1 &−4 & 0
\cr
1&0& 3 &−1& 3 & 1\cr
0&1 &−2 & 1 & 1 &−1
} \right ]
|
so
|
Jb = \left [\array{
0&0& 1 &−1& 2 &−1\cr
0&0 &−2 & 3 &−3 & 3
\cr
0&0& 1 & 1 & 3 & 3\cr
0&0 &−2 & 1 &−4 & 0
\cr
1&0& 3 &−1& 3 & 1\cr
0&1 &−2 & 1 & 1 &−1
} \right ]\left [\array{
{b}_{1}
\cr
{b}_{2}
\cr
{b}_{3}
\cr
{b}_{4}
\cr
{b}_{5}
\cr
{b}_{6} } \right ] = \left [\array{
{b}_{3} − {b}_{4} + 2{b}_{5} − {b}_{6}
\cr
−2{b}_{3} + 3{b}_{4} − 3{b}_{5} + 3{b}_{6}
\cr
{b}_{3} + {b}_{4} + 3{b}_{5} + 3{b}_{6}
\cr
−2{b}_{3} + {b}_{4} − 4{b}_{5}
\cr
{b}_{1} + 3{b}_{3} − {b}_{4} + 3{b}_{5} + {b}_{6}
\cr
{b}_{2} − 2{b}_{3} + {b}_{4} + {b}_{5} − {b}_{6}\cr
} \right ]
|
So by applying the same row operations that row-reduce A to the identity matrix (which we could do with a calculator once {I}_{6} is placed alongside of A), we can then arrive at the result of row-reducing a column of symbols where the vector of constants usually resides. Since the row-reduced version of A has two zero rows, for a consistent system we require that
Now we are exactly back where we were on the first go-round. Notice that we obtain the matrix L as simply the last two rows and last six columns of N. ⊠
This example motivates the remainder of this section, so it is worth careful study. You might attempt to mimic the second approach with the coefficient matrices of Archetype I and Archetype J. We will see shortly that the matrix L contains more information about A than just the column space.
The final matrix that we row-reduced in Example CSANS should look familiar in most respects to the procedure we used to compute the inverse of a nonsingular matrix, Theorem CINM. We will now generalize that procedure to matrices that are not necessarily nonsingular, or even square. First a definition.
Definition EEF
Extended Echelon Form
Suppose A is an
m × n matrix. Add
m new columns to
A that together
equal an m × m identity
matrix to form an m × (n + m)
matrix M. Use row
operations to bring M
to reduced row-echelon form and call the result
N.
N
is the extended reduced row-echelon form of
A,
and we will standardize on names for five submatrices
(B,
C,
J,
K,
L) of
N.
Let B denote the m × n matrix formed from the first n columns of N and let J denote the m × m matrix formed from the last m columns of N. Suppose that B has r nonzero rows. Further partition N by letting C denote the r × n matrix formed from all of the non-zero rows of B. Let K be the r × m matrix formed from the first r rows of J, while L will be the (m − r) × m matrix formed from the bottom m − r rows of J. Pictorially,
|
M = [A\vert {I}_{m}]\mathop{\longrightarrow}\limits_{}^{\text{RREF}}N = [B\vert J] = \left [\array{
C&K |
Example SEEF
Submatrices of extended echelon form
We illustrate Definition EEF with the matrix
A,
|
A = \left [\array{
1 &−1&−2& 7 & 1 & 6\cr
−6 & 2 &−4 &−18 &−3 &−26
\cr
4 &−1& 4 & 10 & 2 & 17\cr
3 &−1 & 2 & 9 & 1 & 12
} \right ]
|
Augmenting with the 4 × 4 identity matrix, M=
|
\left [\array{
1 &−1&−2& 7 & 1 & 6 &1&0&0&0\cr
−6 & 2 &−4 &−18 &−3 &−26 &0 &1 &0 &0
\cr
4 &−1& 4 & 10 & 2 & 17 &0&0&1&0\cr
3 &−1 & 2 & 9 & 1 & 12 &0 &0 &0 &1
} \right ]
|
and row-reducing, we obtain
|
N = \left [\array{
\text{1}&0&2& 1 &0& 3 &0& 1 &1& 1\cr
0&\text{1 } &4 &−6 &0 &−1 &0 & 2 &3 & 0
\cr
0&0&0& 0 &\text{1}& 2 &0&−1&0&−2\cr
0&0 &0 & 0 &0 & 0 &\text{1 } & 2 &2 & 1 } \right ]
|
So we then obtain
You can observe (or verify) the properties of the following theorem with this example. ⊠
Theorem PEEF
Properties of Extended Echelon Form
Suppose that A
is an m × n matrix
and that N
is its extended echelon form. Then
Proof J is the result of applying a sequence of row operations to {I}_{m}, as such J and {I}_{m} are row-equivalent. ℒS\kern -1.95872pt \left ({I}_{m},\kern 1.95872pt 0\right ) has only the zero solution, since {I}_{m} is nonsingular (Theorem NMRRI). Thus, ℒS\kern -1.95872pt \left (J,\kern 1.95872pt 0\right ) also has only the zero solution (Theorem REMES, Definition ESYS) and J is therefore nonsingular (Definition NSM).
To prove the second part of this conclusion, first convince yourself that row operations and the matrix-vector are commutative operations. By this we mean the following. Suppose that F is an m × n matrix that is row-equivalent to the matrix G. Apply to the column vector Fw the same sequence of row operations that converts F to G. Then the result is Gw. So we can do row operations on the matrix, then do a matrix-vector product, or do a matrix-vector product and then do row operations on a column vector, and the result will be the same either way. Since matrix multiplication is defined by a collection of matrix-vector products (Definition MM), if we apply to the matrix product FH the same sequence of row operations that converts F to G then the result will equal GH. Now apply these observations to A.
Write A{I}_{n} = {I}_{m}A and apply the row operations that convert M to N. A is converted to B, while {I}_{m} is converted to J, so we have B{I}_{n} = JA. Simplifying the left side gives the desired conclusion.
For the third conclusion, we now establish the two equivalences
The forward direction of the first equivalence is accomplished by multiplying both sides of the matrix equality by J, while the backward direction is accomplished by multiplying by the inverse of J (which we know exists by Theorem NI since J is nonsingular). The second equivalence is obtained simply by the substitutions given by JA = B.
The first r rows of N are in reduced row-echelon form, since any contiguous collection of rows taken from a matrix in reduced row-echelon form will form a matrix that is again in reduced row-echelon form. Since the matrix C is formed by removing the last n entries of each these rows, the remainder is still in reduced row-echelon form. By its construction, C has no zero rows. C has r rows and each contains a leading 1, so there are r pivot columns in C.
The final m − r rows of N are in reduced row-echelon form, since any contiguous collection of rows taken from a matrix in reduced row-echelon form will form a matrix that is again in reduced row-echelon form. Since the matrix L is formed by removing the first n entries of each these rows, and these entries are all zero (they form the zero rows of B), the remainder is still in reduced row-echelon form. L is the final m − r rows of the nonsingular matrix J, so none of these rows can be totally zero, or J would not row-reduce to the identity matrix. L has m − r rows and each contains a leading 1, so there are m − r pivot columns in L. ■
Notice that in the case where A is a nonsingular matrix we know that the reduced row-echelon form of A is the identity matrix (Theorem NMRRI), so B = {I}_{n}. Then the second conclusion above says JA = B = {I}_{n}, so J is the inverse of A. Thus this theorem generalizes Theorem CINM, though the result is a “left-inverse” of A rather than a “right-inverse.”
The third conclusion of Theorem PEEF is the most telling. It says that x is a solution to the linear system ℒS\kern -1.95872pt \left (A,\kern 1.95872pt y\right ) if and only if x is a solution to the linear system ℒS\kern -1.95872pt \left (B,\kern 1.95872pt Jy\right ). Or said differently, if we row-reduce the augmented matrix \left [\left .A\kern 1.95872pt \right \vert \kern 1.95872pt y\right ] we will get the augmented matrix \left [\left .B\kern 1.95872pt \right \vert \kern 1.95872pt Jy\right ]. The matrix J tracks the cumulative effect of the row operations that converts A to reduced row-echelon form, here effectively applying them to the vector of constants in a system of equations having A as a coefficient matrix. When A row-reduces to a matrix with zero rows, then Jy should also have zero entries in the same rows if the system is to be consistent.
With all the preliminaries in place we can state our main result for this section. In essence this result will allow us to say that we can find linearly independent sets to use in span constructions for all four subsets (null space, column space, row space, left null space) by analyzing only the extended echelon form of the matrix, and specifically, just the two submatrices C and L, which will be ripe for analysis since they are already in reduced row-echelon form (Theorem PEEF).
Theorem FS
Four Subsets
Suppose A is an
m × n matrix with extended
echelon form N. Suppose the
reduced row-echelon form of A
has r nonzero rows.
Then C is the submatrix
of N formed from the
first r rows and the
first n columns and
L is the submatrix
of N formed from
the last m columns
and the last m − r
rows. Then
Proof First, N\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (B\right ) since B is row-equivalent to A (Theorem REMES). The zero rows of B represent equations that are always true in the homogeneous system ℒS\kern -1.95872pt \left (B,\kern 1.95872pt 0\right ), so the removal of these equations will not change the solution set. Thus, in turn, N\kern -1.95872pt \left (B\right ) = N\kern -1.95872pt \left (C\right ).
Second, ℛ\kern -1.95872pt \left (A\right ) = ℛ\kern -1.95872pt \left (B\right ) since B is row-equivalent to A (Theorem REMRS). The zero rows of B contribute nothing to the span that is the row space of B, so the removal of these rows will not change the row space. Thus, in turn, ℛ\kern -1.95872pt \left (B\right ) = ℛ\kern -1.95872pt \left (C\right ).
Third, we prove the set equality C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ) with Definition SE. Begin by showing that C\kern -1.95872pt \left (A\right ) ⊆N\kern -1.95872pt \left (L\right ). Choose y ∈C\kern -1.95872pt \left (A\right ) ⊆ {ℂ}^{m}. Then there exists a vector x ∈ {ℂ}^{n} such that Ax = y (Theorem CSCS). Then for 1 ≤ k ≤ m − r,
So, for all 1 ≤ k ≤ m − r, {\left [Ly\right ]}_{k} ={ \left [0\right ]}_{k}. So by Definition CVE we have Ly = 0 and thus y ∈N\kern -1.95872pt \left (L\right ).
Now, show that N\kern -1.95872pt \left (L\right ) ⊆C\kern -1.95872pt \left (A\right ). Choose y ∈N\kern -1.95872pt \left (L\right ) ⊆ {ℂ}^{m}. Form the vector Ky ∈ {ℂ}^{r}. The linear system ℒS\kern -1.95872pt \left (C,\kern 1.95872pt Ky\right ) is consistent since C is in reduced row-echelon form and has no zero rows (Theorem PEEF). Let x ∈ {ℂ}^{n} denote a solution to ℒS\kern -1.95872pt \left (C,\kern 1.95872pt Ky\right ).
Then for 1 ≤ j ≤ r,
And for r + 1 ≤ k ≤ m,
So for all 1 ≤ i ≤ m, {\left [Bx\right ]}_{i} ={ \left [Jy\right ]}_{i} and by Definition CVE we have Bx = Jy. From Theorem PEEF we know then that Ax = y, and therefore y ∈C\kern -1.95872pt \left (A\right ) (Theorem CSCS). By Definition SE we now have C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ).
Fourth, we prove the set equality ℒ\kern -1.95872pt \left (A\right ) = ℛ\kern -1.95872pt \left (L\right ) with Definition SE. Begin by showing that ℛ\kern -1.95872pt \left (L\right ) ⊆ℒ\kern -1.95872pt \left (A\right ). Choose y ∈ℛ\kern -1.95872pt \left (L\right ) ⊆ {ℂ}^{m}. Then there exists a vector w ∈ {ℂ}^{m−r} such that y = {L}^{t}w (Definition RSM, Theorem CSCS). Then for 1 ≤ i ≤ n,
Since {\left [{A}^{t}y\right ]}_{ i} ={ \left [0\right ]}_{i} for 1 ≤ i ≤ n, Definition CVE implies that {A}^{t}y = 0. This means that y ∈N\kern -1.95872pt \left ({A}^{t}\right ).
Now, show that ℒ\kern -1.95872pt \left (A\right ) ⊆ℛ\kern -1.95872pt \left (L\right ). Choose y ∈ℒ\kern -1.95872pt \left (A\right ) ⊆ {ℂ}^{m}. The matrix J is nonsingular (Theorem PEEF), so {J}^{t} is also nonsingular (Theorem MIT) and therefore the linear system ℒS\kern -1.95872pt \left ({J}^{t},\kern 1.95872pt y\right ) has a unique solution. Denote this solution as x ∈ {ℂ}^{m}. We will need to work with two “halves” of x, which we will denote as z and w with formal definitions given by
Now, for 1 ≤ j ≤ r,
So, by Definition CVE, {C}^{t}z = 0 and the vector z gives us a linear combination of the columns of {C}^{t} that equals the zero vector. In other words, z gives a relation of linear dependence on the the rows of C. However, the rows of C are a linearly independent set by Theorem BRS. According to Definition LICV we must conclude that the entries of z are all zero, i.e. z = 0.
Now, for 1 ≤ i ≤ m, we have
So by Definition CVE, y = {L}^{t}w. The existence of w implies that y ∈ℛ\kern -1.95872pt \left (L\right ), and therefore ℒ\kern -1.95872pt \left (A\right ) ⊆ℛ\kern -1.95872pt \left (L\right ). So by Definition SE we have ℒ\kern -1.95872pt \left (A\right ) = ℛ\kern -1.95872pt \left (L\right ). ■
The first two conclusions of this theorem are nearly trivial. But they set up a pattern of results for C that is reflected in the latter two conclusions about L. In total, they tell us that we can compute all four subsets just by finding null spaces and row spaces. This theorem does not tell us exactly how to compute these subsets, but instead simply expresses them as null spaces and row spaces of matrices in reduced row-echelon form without any zero rows (C and L). A linearly independent set that spans the null space of a matrix in reduced row-echelon form can be found easily with Theorem BNS. It is an even easier matter to find a linearly independent set that spans the row space of a matrix in reduced row-echelon form with Theorem BRS, especially when there are no zero rows present. So an application of Theorem FS is typically followed by two applications each of Theorem BNS and Theorem BRS.
The situation when r = m deserves comment, since now the matrix L has no rows. What is C\kern -1.95872pt \left (A\right ) when we try to apply Theorem FS and encounter N\kern -1.95872pt \left (L\right )? One interpretation of this situation is that L is the coefficient matrix of a homogeneous system that has no equations. How hard is it to find a solution vector to this system? Some thought will convince you that any proposed vector will qualify as a solution, since it makes all of the equations true. So every possible vector is in the null space of L and therefore C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ) = {ℂ}^{m}. OK, perhaps this sounds like some twisted argument from Alice in Wonderland. Let us try another argument that might solidly convince you of this logic.
If r = m, when we row-reduce the augmented matrix of ℒS\kern -1.95872pt \left (A,\kern 1.95872pt b\right ) the result will have no zero rows, and all the leading 1’s will occur in first n columns, so by Theorem RCLS the system will be consistent. By Theorem CSCS, b ∈C\kern -1.95872pt \left (A\right ). Since b was arbitrary, every possible vector is in the column space of A, so we again have C\kern -1.95872pt \left (A\right ) = {ℂ}^{m}. The situation when a matrix has r = m is known by the term full rank, and in the case of a square matrix coincides with nonsingularity (see Exercise FS.M50).
The properties of the matrix L described by this theorem can be explained informally as follows. A column vector y ∈ {ℂ}^{m} is in the column space of A if the linear system ℒS\kern -1.95872pt \left (A,\kern 1.95872pt y\right ) is consistent (Theorem CSCS). By Theorem RCLS, the reduced row-echelon form of the augmented matrix \left [\left .A\kern 1.95872pt \right \vert \kern 1.95872pt y\right ] of a consistent system will have zeros in the bottom m − r locations of the last column. By Theorem PEEF this final column is the vector Jy and so should then have zeros in the final m − r locations. But since L comprises the final m − r rows of J, this condition is expressed by saying y ∈N\kern -1.95872pt \left (L\right ).
Additionally, the rows of J
are the scalars in linear combinations of the rows of
A that create the
rows of B. That
is, the rows of J
record the net effect of the sequence of row operations that takes
A to its reduced row-echelon
form, B. This can be seen in the
equation JA = B (Theorem PEEF).
As such, the rows of L
are scalars for linear combinations of the rows of
A
that yield zero rows. But such linear combinations are precisely the
elements of the left null space. So any element of the row space of
L is also an element of
the left null space of A.
We will now illustrate Theorem FS with a few examples.
Example FS1
Four subsets, #1
In Example SEEF we found the five relevant submatrices of the matrix
|
A = \left [\array{
1 &−1&−2& 7 & 1 & 6\cr
−6 & 2 &−4 &−18 &−3 &−26
\cr
4 &−1& 4 & 10 & 2 & 17\cr
3 &−1 & 2 & 9 & 1 & 12
} \right ]
|
To apply Theorem FS we only need C and L,
Then we use Theorem FS to obtain
Boom! ⊠
Example FS2
Four subsets, #2
Now lets return to the matrix A
that we used to motivate this section in Example CSANS,
|
A = \left [\array{
10 & 0 & 3 & 8 & 7\cr
−16 &−1 &−4 &−10 &−13
\cr
−6 & 1 &−3& −6 & −6\cr
0 & 2 &−2 & −3 & −2
\cr
3 & 0 & 1 & 2 & 3\cr
−1 &−1 & 1 & 1 & 0 } \right ]
|
We form the matrix M by adjoining the 6 × 6 identity matrix {I}_{6},
|
M = \left [\array{
10 & 0 & 3 & 8 & 7 &1&0&0&0&0&0\cr
−16 &−1 &−4 &−10 &−13 &0 &1 &0 &0 &0 &0
\cr
−6 & 1 &−3& −6 & −6 &0&0&1&0&0&0\cr
0 & 2 &−2 & −3 & −2 &0 &0 &0 &1 &0 &0
\cr
3 & 0 & 1 & 2 & 3 &0&0&0&0&1&0\cr
−1 &−1 & 1 & 1 & 0 &0 &0 &0 &0 &0 &1 } \right ]
|
and row-reduce to obtain N
|
N = \left [\array{
\text{1}&0&0&0& 2 &0&0& 1 &−1& 2 &−1\cr
0&\text{1 } &0 &0 &−3 &0 &0 &−2 & 3 &−3 & 3
\cr
0&0&\text{1}&0& 1 &0&0& 1 & 1 & 3 & 3\cr
0&0 &0 &\text{1 } &−2 &0 &0 &−2 & 1 &−4 & 0
\cr
0&0&0&0& 0 &\text{1}&0& 3 &−1& 3 & 1\cr
0&0 &0 &0 & 0 &0 &\text{1 } &−2 & 1 & 1 &−1
} \right ]
|
To find the four subsets for A, we only need identify the 4 × 5 matrix C and the 2 × 6 matrix L,
Then we apply Theorem FS,
The next example is just a bit different since the matrix has more rows than columns, and a trivial null space.
Example FSAG
Four subsets, Archetype G
Archetype G and Archetype H are both systems of
m = 5 equations
in n = 2
variables. They have identical coefficient matrices, which we will denote here as the
matrix G,
|
G = \left [\array{
2 & 3\cr
−1 & 4
\cr
3 &10\cr
3 &−1
\cr
6 & 9 } \right ]
|
Adjoin the 5 × 5 identity matrix, {I}_{5}, to form
|
M = \left [\array{
2 & 3 &1&0&0&0&0\cr
−1 & 4 &0 &1 &0 &0 &0
\cr
3 &10&0&0&1&0&0\cr
3 &−1 &0 &0 &0 &1 &0
\cr
6 & 9 &0&0&0&0&1 } \right ]
|
This row-reduces to
|
N = \left [\array{
\text{1}&0&0&0&0& {3\over _
11} & {1\over _
33}
\cr
0&\text{1}&0&0&0&−{2\over _
11}& {1\over _
11}
\cr
0&0&\text{1}&0&0& 0 &−{1\over
3}
\cr
0&0&0&\text{1}&0& 1 &−{1\over
3}
\cr
0&0&0&0&\text{1}& 1 &−1 } \right ]
|
The first n = 2 columns contain r = 2 leading 1’s, so we obtain C as the 2 × 2 identity matrix and extract L from the final m − r = 3 rows in the final m = 5 columns.
Then we apply Theorem FS,
As mentioned earlier, Archetype G is consistent, while Archetype H is inconsistent. See if you can write the two different vectors of constants from these two archetypes as linear combinations of the two vectors in C\kern -1.95872pt \left (G\right ). How about the two columns of G, can you write each individually as a linear combination of the two vectors in C\kern -1.95872pt \left (G\right )? They must be in the column space of G also. Are your answers unique? Do you notice anything about the scalars that appear in the linear combinations you are forming? ⊠
Example COV and Example CSROI each describes the column space of the coefficient matrix from Archetype I as the span of a set of r = 3 linearly independent vectors. It is no accident that these two different sets both have the same size. If we (you?) were to calculate the column space of this matrix using the null space of the matrix L from Theorem FS then we would again find a set of 3 linearly independent vectors that span the range. More on this later.
So we have three different methods to obtain a description of the column space of a matrix as the span of a linearly independent set. Theorem BCS is sometimes useful since the vectors it specifies are equal to actual columns of the matrix. Theorem BRS and Theorem CSRST combine to create vectors with lots of zeros, and strategically placed 1’s near the top of the vector. Theorem FS and the matrix L from the extended echelon form gives us a third method, which tends to create vectors with lots of zeros, and strategically placed 1’s near the bottom of the vector. If we don’t care about linear independence we can also appeal to Definition CSM and simply express the column space as the span of all the columns of the matrix, giving us a fourth description.
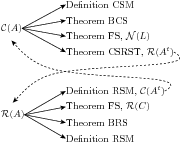
With Theorem CSRST and Definition RSM, we can compute column spaces with theorems about row spaces, and we can compute row spaces with theorems about row spaces, but in each case we must transpose the matrix first. At this point you may be overwhelmed by all the possibilities for computing column and row spaces. Diagram CSRST is meant to help. For both the column space and row space, it suggests four techniques. One is to appeal to the definition, another yields a span of a linearly independent set, and a third uses Theorem FS. A fourth suggests transposing the matrix and the dashed line implies that then the companion set of techniques can be applied. This can lead to a bit of silliness, since if you were to follow the dashed lines twice you would transpose the matrix twice, and by Theorem TT would accomplish nothing productive.
Although we have many ways to describe a column space, notice that one tempting strategy will usually fail. It is not possible to simply row-reduce a matrix directly and then use the columns of the row-reduced matrix as a set whose span equals the column space. In other words, row operations do not preserve column spaces (however row operations do preserve row spaces, Theorem REMRS). See Exercise CRS.M21.
|
A = \left [\array{
2 & 1 &−3& 4\cr
−1 &−1 & 2 &−1
\cr
0 &−1& 1 & 2} \right ]
|
|
A = \left [\array{
−9& 5 &−3\cr
2 &−1 & 1
\cr
−5& 3 &−1} \right ]
|
C20 Example FSAG concludes with several questions. Perform the analysis
suggested by these questions.
Contributed by Robert Beezer
C25 Given the matrix A below, use the extended echelon form of A to answer each part of this problem. In each part, find a linearly independent set of vectors, S, so that the span of S, \left \langle S\right \rangle , equals the specified set of vectors.
|
A = \left [\array{
−5& 3 &−1\cr
−1 & 1 & 1
\cr
−8& 5 &−1\cr
3 &−2 & 0
} \right ]
|
(a) The row space of A,
ℛ\kern -1.95872pt \left (A\right ).
(b) The column space of A,
C\kern -1.95872pt \left (A\right ).
(c) The null space of A,
N\kern -1.95872pt \left (A\right ).
(d) The left null space of A,
ℒ\kern -1.95872pt \left (A\right ).
Contributed by Robert Beezer Solution [823]
C26 For the matrix D
below use the extended echelon form to find
(a) a linearly independent set whose span is the column space of
D.
(b) a linearly independent set whose span is the left null space of
D.
Contributed by Robert Beezer Solution [825]
C41 The following archetypes are systems of equations. For each system, write
the vector of constants as a linear combination of the vectors in the span
construction for the column space provided by Theorem FS and Theorem BNS
(these vectors are listed for each of these archetypes).
Archetype A
Archetype B
Archetype C
Archetype D
Archetype E
Archetype F
Archetype G
Archetype H
Archetype I
Archetype J
Contributed by Robert Beezer
C43 The following archetypes are either matrices or systems of equations with
coefficient matrices. For each matrix, compute the extended echelon form
N and identify
the matrices C
and L.
Using Theorem FS, Theorem BNS and Theorem BRS express the null space, the
row space, the column space and left null space of each coefficient matrix as a
span of a linearly independent set.
Archetype A
Archetype B
Archetype C
Archetype D/Archetype E
Archetype F
Archetype G/Archetype H
Archetype I
Archetype J
Archetype K
Archetype L
Contributed by Robert Beezer
C60 For the matrix B
below, find sets of vectors whose span equals the column space of
B
(C\kern -1.95872pt \left (B\right )) and
which individually meet the following extra requirements.
(a) The set illustrates the definition of the column space.
(b) The set is linearly independent and the members of the set are columns of
B.
(c) The set is linearly independent with a “nice pattern of zeros and ones” at the
top of each vector.
(d) The set is linearly independent with a “nice pattern of zeros and ones” at
the bottom of each vector.
|
B = \left [\array{
2 &3&1& 1\cr
1 &1 &0 & 1
\cr
−1&2&3&−4 } \right ]
|
Contributed by Robert Beezer Solution [827]
C61 Let A be the matrix below, and find the indicated sets with the requested properties.
|
A = \left [\array{
2 &−1& 5 &−3\cr
−5 & 3 &−12 & 7
\cr
1 & 1 & 4 &−3 } \right ]
|
(a) A linearly independent set S
so that C\kern -1.95872pt \left (A\right ) = \left \langle S\right \rangle and
S is composed of
columns of A.
(b) A linearly independent set S
so that C\kern -1.95872pt \left (A\right ) = \left \langle S\right \rangle and
the vectors in S
have a nice pattern of zeros and ones at the top of the vectors.
(c) A linearly independent set S
so that C\kern -1.95872pt \left (A\right ) = \left \langle S\right \rangle and
the vectors in S
have a nice pattern of zeros and ones at the bottom of the vectors.
(d) A linearly independent set S
so that ℛ\kern -1.95872pt \left (A\right ) = \left \langle S\right \rangle .
Contributed by Robert Beezer Solution [830]
M50 Suppose that A
is a nonsingular matrix. Extend the four conclusions of Theorem FS in
this special case and discuss connections with previous results (such as
Theorem NME4).
Contributed by Robert Beezer
M51 Suppose that A
is a singular matrix. Extend the four conclusions of Theorem FS in this special
case and discuss connections with previous results (such as Theorem NME4).
Contributed by Robert Beezer
C25 Contributed by Robert Beezer Statement [818]
Add a 4 × 4 identity matrix
to the right of A to form
the matrix M and then
row-reduce to the matrix N,
|
M = \left [\array{
−5& 3 &−1&1&0&0&0\cr
−1 & 1 & 1 &0 &1 &0 &0
\cr
−8& 5 &−1&0&0&1&0\cr
3 &−2 & 0 &0 &0 &0 &1
} \right ]\mathop{\longrightarrow}\limits_{}^{\text{RREF}}\left [\array{
\text{1}&0&2&0&0&−2&−5\cr
0&\text{1 } &3 &0 &0 &−3 &−8
\cr
0&0&0&\text{1}&0&−1&−1\cr
0&0 &0 &0 &\text{1 } & 1 & 3 } \right ] = N
|
To apply Theorem FS in each of these four parts, we need the two matrices,
(a)
(b)
(c)
(d)
C26 Contributed by Robert Beezer Statement [818]
For both parts, we need the extended echelon form of the matrix.
From this matrix we extract the last two rows, in the last four columns to form the matrix L,
(a) By Theorem FS and Theorem BNS we have
(b) By Theorem FS and Theorem BRS we have
C60 Contributed by Robert Beezer Statement [820]
(a) The definition of the column space is the span of the set of columns
(Definition CSM). So the desired set is just the four columns of
B,
|
S = \left \{\left [\array{
2\cr
1
\cr
−1 } \right ],\kern 1.95872pt \left [\array{
3\cr
1
\cr
2 } \right ],\kern 1.95872pt \left [\array{
1\cr
0
\cr
3 } \right ],\kern 1.95872pt \left [\array{
1\cr
1
\cr
−4 } \right ]\right \}
|
(b) Theorem BCS suggests row-reducing the matrix and using the columns of B that correspond to the pivot columns.
|
B\mathop{\longrightarrow}\limits_{}^{\text{RREF}}\left [\array{
\text{1}&0&−1& 2\cr
0&\text{1 } & 1 &−1
\cr
0&0& 0 & 0 } \right ]
|
So the pivot columns are numbered by elements of D = \left \{1,\kern 1.95872pt 2\right \}, so the requested set is
|
S = \left \{\left [\array{
2\cr
1
\cr
−1 } \right ],\kern 1.95872pt \left [\array{
3\cr
1
\cr
2 } \right ]\right \}
|
(c) We can find this set by row-reducing the transpose of B, deleting the zero rows, and using the nonzero rows as column vectors in the set. This is an application of Theorem CSRST followed by Theorem BRS.
|
{
B}^{t}\mathop{\longrightarrow}\limits_{}^{\text{RREF}}\left [\array{
\text{1}&0& 3\cr
0&\text{1 } &−7
\cr
0&0& 0\cr
0&0 & 0 } \right ]
|
So the requested set is
|
S = \left \{\left [\array{
1\cr
0
\cr
3 } \right ],\kern 1.95872pt \left [\array{
0\cr
1
\cr
−7 } \right ]\right \}
|
(d) With the column space expressed as a null space, the vectors obtained via Theorem BNS will be of the desired shape. So we first proceed with Theorem FS and create the extended echelon form,
|
\left [\left .B\kern 1.95872pt \right \vert \kern 1.95872pt {I}_{3}\right ] = \left [\array{
2 &3&1& 1 &1&0&0\cr
1 &1 &0 & 1 &0 &1 &0
\cr
−1&2&3&−4&0&0&1 } \right ]\mathop{\longrightarrow}\limits_{}^{\text{RREF}}\left [\array{
\text{1}&0&−1& 2 &0& {2\over
3} &{−1\over
3}
\cr
0&\text{1}& 1 &−1&0& {1\over
3} & {1\over
3}
\cr
0&0& 0 & 0 &\text{1}&{−7\over
3} &{−1\over
3} } \right ]
|
So, employing Theorem FS, we have C\kern -1.95872pt \left (B\right ) = N\kern -1.95872pt \left (L\right ), where
|
L = \left [\array{
\text{1}&{−7\over
3} &{−1\over
3} } \right ]
|
We can find the desired set of vectors from Theorem BNS as
|
S = \left \{\left [\array{
{7\over
3}
\cr
1\cr
0 } \right ],\kern 1.95872pt \left [\array{
{1\over
3}
\cr
0\cr
1 } \right ]\right \}
|
C61 Contributed by Robert Beezer Statement [821]
(a) First find a matrix B
that is row-equivalent to A
and in reduced row-echelon form
|
B = \left [\array{
\text{1}&0&3&−2\cr
0&\text{1 } &1 &−1
\cr
0&0&0& 0 } \right ]
|
By Theorem BCS we can choose the columns of A that correspond to dependent variables (D = \left \{1, 2\right \}) as the elements of S and obtain the desired properties. So
|
S = \left \{\left [\array{
2\cr
−5
\cr
1 } \right ],\kern 1.95872pt \left [\array{
−1\cr
3
\cr
1 } \right ]\right \}
|
(b) We can write the column space of A as the row space of the transpose (Theorem CSRST). So we row-reduce the transpose of A to obtain the row-equivalent matrix C in reduced row-echelon form
|
C = \left [\array{
1&0&8\cr
0&1 &3
\cr
0&0&0\cr
0&0 &0} \right ]
|
The nonzero rows (written as columns) will be a linearly independent set that spans the row space of {A}^{t}, by Theorem BRS, and the zeros and ones will be at the top of the vectors,
|
S = \left \{\left [\array{
1\cr
0
\cr
8 } \right ],\kern 1.95872pt \left [\array{
0\cr
1
\cr
3 } \right ]\right \}
|
(c) In preparation for Theorem FS, augment A with the 3 × 3 identity matrix {I}_{3} and row-reduce to obtain the extended echelon form,
|
\left [\array{
1&0&3&−2&0&−{1\over
8}& {3\over
8}
\cr
0&1&1&−1&0& {1\over
8} & {5\over
8}
\cr
0&0&0& 0 &1& {3\over
8} &−{1\over
8} } \right ]
|
Then since the first four columns of row 3 are all zeros, we extract
|
L = \left [\array{
\text{1}&{3\over
8}&−{1\over
8} } \right ]
|
Theorem FS says that C\kern -1.95872pt \left (A\right ) = N\kern -1.95872pt \left (L\right ). We can then use Theorem BNS to construct the desired set S, based on the free variables with indices in F = \left \{2, 3\right \} for the homogeneous system ℒS\kern -1.95872pt \left (L,\kern 1.95872pt 0\right ), so
|
S = \left \{\left [\array{
−{3\over
8}
\cr
1\cr
0 } \right ],\kern 1.95872pt \left [\array{
{1\over
8}
\cr
0\cr
1 } \right ]\right \}
|
Notice that the zeros and ones are at the bottom of the vectors.
(d) This is a straightforward application of Theorem BRS. Use the row-reduced
matrix B
from part (a), grab the nonzero rows, and write them as column vectors,
|
S = \left \{\left [\array{
1\cr
0
\cr
3\cr
−2 } \right ],\kern 1.95872pt \left [\array{
0\cr
1
\cr
1\cr
−1 } \right ]\right \}
|
Theorem VSPM
These are the fundamental rules for working with the addition, and scalar
multiplication, of matrices. We saw something very similar in the previous chapter
(Theorem VSPCV). Together, these two definitions will provide our definition for
the key definition, Definition VS.
Theorem SLEMM
Theorem SLSLC connected linear combinations with systems of equations.
Theorem SLEMM connects the matrix-vector product (Definition MVP) and
column vector equality (Definition CVE) with systems of equations. We’ll see this
one regularly.
Theorem EMP
This theorem is a workhorse in Section MM and will continue to make regular
appearances. If you want to get better at formulating proofs, the application of
this theorem can be a key step in gaining that broader understanding. While it
might be hard to imagine Theorem EMP as a definition of matrix multiplication,
we’ll see in Exercise MR.T80 that in theory it is actually a better definition of
matrix multiplication long-term.
Theorem CINM
The inverse of a matrix is key. Here’s how you can get one if you know how to
row-reduce.
Theorem NI
“Nonsingularity” or “invertibility”? Pick your favorite, or show your versatility by
using one or the other in the right context. They mean the same thing.
Theorem CSCS
Given a coefficient matrix, which vectors of constants create consistent systems.
This theorem tells us that the answer is exactly those column vectors in the
column space. Conversely, we also use this teorem to test for membership in the
column space by checking the consistency of the appropriate system of
equations.
Theorem BCS
Another theorem that provides a linearly independent set of vectors whose span
equals some set of interest (a column space this time).
Theorem BRS
Yet another theorem that provides a linearly independent set of vectors whose
span equals some set of interest (a row space).
Theorem CSRST
Column spaces, row spaces, transposes, rows, columns. Many of the connections
between these objects are based on the simple observation captured in this
theorem. This is not a deep result. We state it as a theorem for convenience, so we
can refer to it as needed.
Theorem FS
This theorem is inherently interesting, if not computationally satisfying. Null
space, row space, column space, left null space — here they all are, simply by row
reducing the extended matrix and applying Theorem BNS and Theorem BCS
twice (each). Nice.